A week ago I partly fixed my site Today’s Guardian, but it wasn’t fully repaired. Now it is.
The problem was that the script which creates the site each day scraped the content of a web page to get the list of articles in that day’s edition of the paper, which were then fetched one-by-one from the Guardian’s API. Inevitably that web page changed, my script didn’t understand the new HTML, and it didn’t seem an easy job to fix this fragile part of the process.
When I last did a chunk of work on the site there was no way to recreate an edition of the newspaper solely using the API. Thankfully that’s changed and you can now:
-
Set
use-datetonewspaper-edition, andfrom-dateand(?)to-dateto theYYYY-MM-DDdate in question. -
Set
tagsto includenewspaper-book(a “book” being the section of the printed paper, such as “Main section”, “G2” or “Sport”). -
Include
newspaperPageNumberin theshow-fieldsparameter.
This will fetch all the articles from that day’s paper, each accompanied by a description of which “book” it’s in, and include the page within that book the article is on. For example, here is the kind of query I’m doing, in the Content API explorer.
(There’s another tag, newspaper-book-section which is the section within the newspaper-book, such as “Editorials & reply” or “UK news”. I haven’t done anything with this yet.)
So I’ve now replaced the previous fragile and lengthy process with one which fetches all the articles in a single API request (or two, should there ever be more than 200 articles in one edition). A bit of shuffling of data later and I’ve reconstructed the day’s paper.
Not only does this make the script much faster to run, but it hopefully means the site will be more robust, and the sections of the paper will make more sense — previously there were some strange odds and ends appearing.
There are some oddities — it seems like one or two articles a day have no page number, so I’m currently leaving them out. And yesterday there was an article with no newspaper-book, so I’d also omit that.
And I’m a bit confused by the variety of “sections” an article could be in. For example, an article might have a sectionId of “Business”, while its newspaper-book-section might have a webTitle of “Top stories” and a sectionName of “From the Guardian”. A different article might have “UK news” for all three parameters. For now I’m only showing the first.
I took the opportunity to make a few more under-the-hood improvements and one more visible one: any “Opinion” articles that include a URL for the author’s photo now include that photo. Previously, because every article looks so similar in my design, I was always momentarily confused when I started reading something that didn’t feel like “news”. I’d then realise it was a “column” and I could ignore it. So now, the sight of an author portrait will be a sign (for me) that I can swiftly move on.
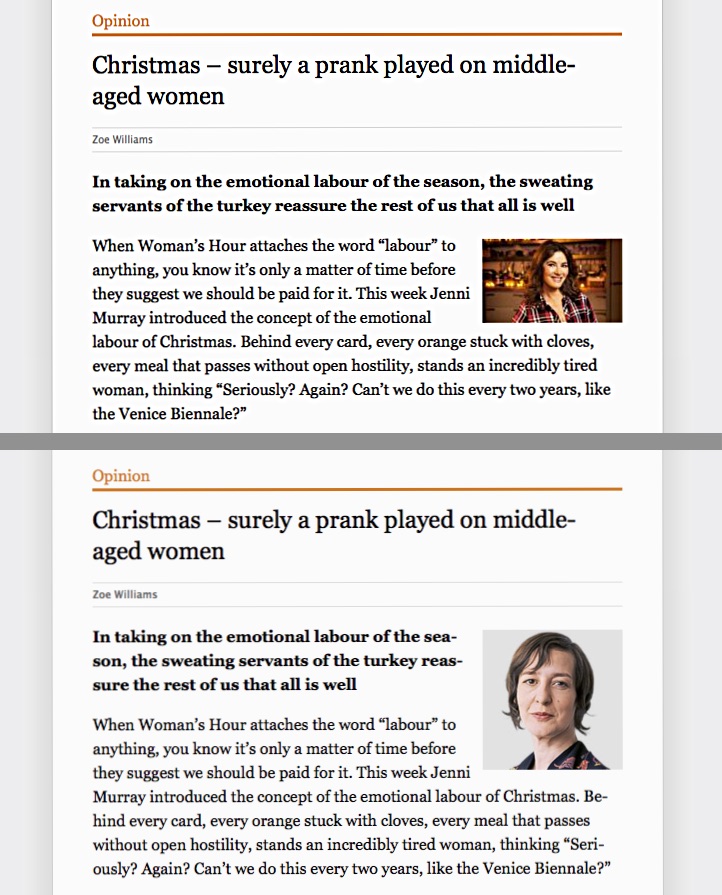 Above, looks like everything else. Below, a more obviously ignorable piece of opinion.
Above, looks like everything else. Below, a more obviously ignorable piece of opinion.
There’s still room for improvement. For example, although the articles are sorted by page number, some things still feel slightly out of order. The letters page, for example, contains articles other than letters. While everything from that page will be grouped together, the letters won’t necessarily be consecutive within that group.
But this all seems good enough for the moment and I have other things to fix and update before Christmas. Happy reading!
My thanks to two former Guardian employees, Paul Lloyd and Cantlin Ashrowan, for pointing me towards this solution.
Commenting is disabled on posts once they’re 30 days old.